클라우드 컴퓨팅을 이해하기 전에 받드시 한번쯤을 봐야할 이미지…
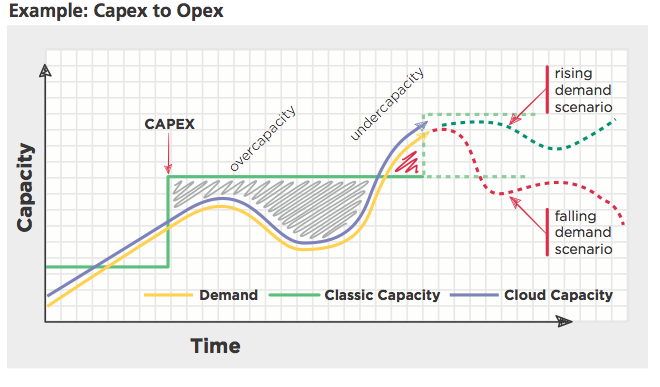
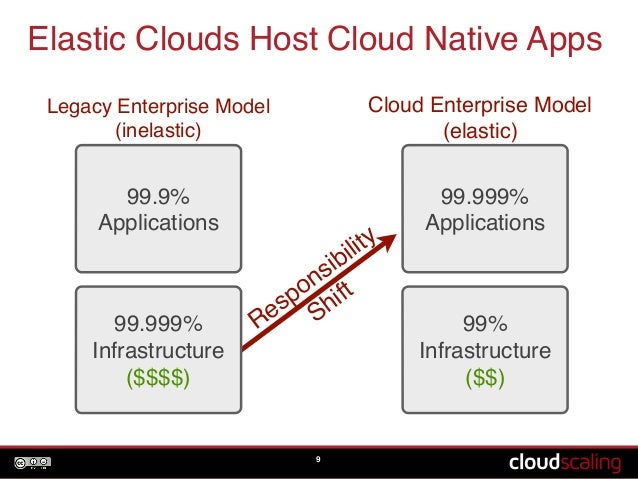
클라우드 컴퓨팅을 이해하기 전에 받드시 한번쯤을 봐야할 이미지…
지난주에 구글과 미팅을 하다가 아무래도 우리가 OpenStack 및 클라우드에 중심을 두고 이야기하다 보니 당연히 Kubernetes 이야기가 나왔다.
그들의 이야기로는 알려진 것 처럼 구글에서는 워크로드의 99%가 컨테이너 위에서 동작하고, 그리고 그 것을 오픈소스화한 kubernetes가 1.0이 나오면 엄청난 발전을 할 것이라고 하도 자랑을 해서 다시 한번 봐보기로 했다.
물론 그 전에 봤을때 아직은 쓸만한 것이 아니라고(그때는 홈페이지도 볼만한 수준이 아니였다.. 뭐.. 그건 지금도 마찬가지) 판단했지만, 그 이후에 mirantis가 google과 kubernetes를 오픈스택에 올리는 것을 협의한다는 뉴스(murano 이야기인데, 그게 murano의 기반을 kubernetes로 간다고 생각했는데, 지금보면 murano app에 kubernetes를 포함하는 것 아닐까 한다.)까지 나와서 다시 한번 봤다.
CoreOS에서 나온 Key/Value Store로 kubernetes는 모든 데이터를 여기가 저장한다. 나중에 나오는 flannel도 여기다 데이터를 저장한다.
etcd는 여러 많은 곳에서 production에 사용하고 있다고 하니깐.. 알아서 쓰시면 되겠다.
덧) Consul를 사용하는게 더 나을 것 같다.
master는 사용자 API Request를 받아들이고, Application replica를 유지하고, kube-apiserver, kube-controller-manager, kube-scheduler로 구성된다.
etcd를 모니터하고 있다가 replica 설정이 변경되면 API를 이용해서 replication을 유지한다.minion은 그냥 worker다. minion을 사전에서 찾아보면 앞잡이, 부하라는 뜻이다.
kube-proxy를 통신을 위한 iptables 설정하는 등의 역할 수행Application은 Container의 그룹인 pod와 이를 관리하는 replicationController, 이를 외부와 통신하는 Service로 구성된다. 자세한 내용은 Design 문서를 참고한다.
ReplicationController는 확장하는 단위다. 간단히 말해서 AWS AutoScalingGroup의 단위가 된다. guestbook-go.
그리고 이 한 단위는 container의 묶음이 된다. 이 묶음 하나를 POD라고 한다. 즉 ReplicationController는 POD로 갯수를 관리한다.
nginx / uwsgi + flak / api / cache/ db로 구성된 App을 생각해보면 아래처럼 Scale Group을 나누게 될 것이고, 이게 ReplicationController가 된다.
이렇게 ReplicationCluster가 여러 POD를 구성하는데, 각 POD는 독립적인 IP를 가진다. 근데 이를 외부 또는 내부에서 접근하기 위해서는 ElasticIP(또는 vip)와 같은 방식으로 접근하는데 이게 Service이다.
Kubernetes의 네트워크 모델은 GCE(Google Compuging Engine)에 종속적인 느낌이다. Network provider가 연결된 NIC에 subnet을 routing 해주는 기능이 필요하다(이 기능을 GCE는 하고 있다).
GCE가 아니면 VALN, flannel 또는 다른 것(Weave, OpenVSwitch…)을 이용해서 POD간에 internal network을 overlay network으로 구성하면 된다.
하지만 이것도 문제가 있다.
kubenetes pod에서 사용할 큰 VLAN/ Subnet을 잡아놓고, 각 Node마다 subnet을 작게 할당해주면 가능하다.
하지만, 이렇게 할 경우 사람 손으로 한다는 것은 힘들고, 자동화를 시켜야한다. 자동화를 한다는 것에 중요한 것은 이 프로젝트를 본격적으로 해보겠다는 이야기인데, 익숙해지기 그리고 완전히 파악하기 전까지는 힘든 일이겠다.
기본적으로 노드(minion)에 subnet(ex /24)를 할당하게 되어있어서, 네트워크 자원을 효율적으로 쓰지 못한다. /24를 할당했다면 255개의 POD를 수용가능하지만, 이건 컴퓨팅 파워, Application의 성격에 달린 문제이기 때문에 완전히 효율적을 사용하지 못한다.
POD Network은 overlay network이므로 flannel이 설치된 곳에서만 사용이 가능하다. 결국 외부로 통신하기 위해서는 한쪽에서 LB 또는 NAT를 이용하여 gateway 기능을 해줘야한다. 결국 여기서 traffic 집중 현상이 발생하다.
ReplicationController로 부터 시작하는 개념은 좋다. 이렇게 가면서 자연스럽게 클라우드/클러스터 중심으로 생각을 시작할 수 있을 것 같다.
multi tenent/ 인증 모델이 없다. endpoint만 알면 아무나 사용할 수 있는 구조이다.
kube-proxy에 traffic이 몰린다. 향후 계획에는 부하를 줄이기 위해서 user space proxy인 kube-proxy 대신 iptables NAT를 이용한다고 하지만, 여전히 software 기반이기 때무에 한계는 있을 것이다.
multi-master가 아니다. 뭐 이건 중요한 문제이기 때문에 곧 해결될 것으로 보인다.
etcd가 신뢰 할 만한지는 아직 모르겠다..
역시 가장 큰 문제는 GCE에 종속된 네트워크 구조이다. 이거 때문에 GCE가 아닌 환경에서는 상당히 고생하지 않을까한다.
이거 하면서 OpenStack에 어떻게 접목시킬까 고민하고 있었는데… 뭔가 실마리를 찾앗다. 이거 수정하려면 go를 공부해야하는데.. … 음… golang은 왠지 안땡겨서…
iptables의 chain이 적용되는 순서를 쉽게 보고싶다면 http://atoato88.hatenablog.com/entry/2014/01/25/133852 를 참조~
+--------------------------------+
| v
+-------------------------+ +--------------------------+ +------------------------------+ +------------------------------+ +------------------------------+
| FORWARD | --> | neutron-openvswi-FORWARD | --> | neutron-openvswi-sg-chain | --> | neutron-openvswi-i286a46e9-d | --> | neutron-openvswi-sg-fallback |
+-------------------------+ +--------------------------+ +------------------------------+ +------------------------------+ +------------------------------+
| ^
+-------------------------------+ |
v |
+-------------------------+ +--------------------------+ +------------------------------+ |
| OUTPUT | --> | neutron-filter-top | --> | neutron-openvswi-local | |
+-------------------------+ +--------------------------+ +------------------------------+ |
| |
| |
v |
+-------------------------+ |
| neutron-openvswi-OUTPUT | |
+-------------------------+ |
+-------------------------+ +--------------------------+ +------------------------------+ |
| INPUT | --> | neutron-openvswi-INPUT | --> | neutron-openvswi-o286a46e9-d | -------------------------------------------+
+-------------------------+ +--------------------------+ +------------------------------+
|
|
v
+-------------------------+ +------------------------------+
| nova-api-FORWARD | | neutron-openvswi-s286a46e9-d |
+-------------------------+ +------------------------------+
+-------------------------+
| nova-api-INPUT |
+-------------------------+
+-------------------------+
| nova-api-OUTPUT |
+-------------------------+
+-------------------------+
| nova-api-local |
+-------------------------+
+-------------------------+
| nova-filter-top |
+-------------------------+
thanks rick
keystone bootstrap 이란 명령이 있는 것을 오늘 처음 알았다.. ^^
\1. 프로젝트를 만들고 2. 유저를 만들고 3. 해당 유저를 프로젝트에 어떤 롤로 지정한다..
이것을 한번에 수행한다. 이전에 이거 하려고 몇번 명령 내렸던 뻘짓을…
$ keystone help bootstrap
usage: keystone bootstrap [--user-name <user-name>] --pass <password>
[--role-name <role-name>]
[--tenant-name <tenant-name>]
Grants a new role to a new user on a new tenant, after creating each.
Arguments:
--user-name <user-name>
The name of the user to be created (default="admin").
--pass <password> The password for the new user.
--role-name <role-name>
The name of the role to be created and granted to the
user (default="admin").
--tenant-name <tenant-name>
The name of the tenant to be created
(default="admin").
Security Group은 기본설정으로 모든 inbound traffic을 차단하고 모든 outbound traffic을 허용합니다. 그리고 같은 tenant의 인스턴스는 모든 traffic을 허용하도록 되어 있습니다.
Public Cloud를 고려하는 상황이라면 이 정책은 맞는 정책입니다. 그런데 Private Cloud라면 조금 상황이 달라집니다. 일반적으로 회사에서는 내부의 traffic에 대한 제한을 걸지않고 있습니다(상황은 다 다르겠지만). 그리고 보안팀의 정책에 따라서 보안구역을 나누어 ACL을 설정하는 형태로 운영이 되겠죠.
더 구제적으로 따져가서 오픈스택을 개발용 인프라로 사용할 경우, 개발자에게 모든 트래픽이 막혀있으니, 필요할 경우는 알아서 여세요..가 그리 쉽지 않다. 그리고 사용하다보니 결국 개발자들은 모든 tcp/udp traffic을 허용하고 사용하고 있다.
특히나 인스턴스 만들고 ping, ssh가 안되니, 처음 접하는 사람은 조금 당황하는 현상이 발생한다.
nova-network을 사용하는 경우는 default security의 rule을 수정하는 기능이 들어가 있다.
nova secgroup-list-default-rules
nova secgroup-add-default-rule
nova secgroup-delete-default-rule
하지만 neutron에는 이 기능이 작동하지 않는데, 이는 해당 API의 기능을 neutron에서 구현하지 않고 있다. 물론 이 기능을 구현하기 위한 blueprint도 등록이 되어 있지만, 현재는 abandon 상태다.
어쨌든 우리는 neutron을 사용하고 있고, 이게 불편해서 그냥 모든 inbound traffic을 혀용한다면 간단하게 소스를 수정하면 된다.
diff --git a/neutron/db/securitygroups_db.py b/neutron/db/securitygroups_db.py
index 92dcc7a..2438b53 100644
--- a/neutron/db/securitygroups_db.py
+++ b/neutron/db/securitygroups_db.py
@@ -143,13 +143,12 @@ class SecurityGroupDbMixin(ext_sg.SecurityGroupPluginBase):
tenant_id=security_group_db['tenant_id']))
for ethertype in ext_sg.sg_supported_ethertypes:
if default_sg:
- # Allow intercommunication
+ # Allow all ingress traffic
ingress_rule = SecurityGroupRule(
id=uuidutils.generate_uuid(), tenant_id=tenant_id,
security_group=security_group_db,
direction='ingress',
- ethertype=ethertype,
- source_group=security_group_db)
+ ethertype=ethertype)
context.session.add(ingress_rule)
egress_rule = SecurityGroupRule(
이렇게 하면 이제 모든 inbound traffic은 아주 잘 들어온다.
이전 블로그가 WordPress로 되어 있었습니다. 녜.. php로 되어있는데요.. 어느 순간 wordpress가 알아서 upgrade되더니만 갑자기 MySQL Database 연결오류를 내고 정신을 못차립니다.
고치느니.. 그냥 다른 블로그 툴로 넘어가렵니다.. ㅎㅎㅎ(뭐.. 고치는 것은 금방이었지만요..)
업그레이드 되면서 플러그인들도 업그레이드 안되는 것도 많고… :)
찾아보니깐 역시나 좋은 툴이 있습니다.
하지만 역시나 완벽할 수는 없고.. 여기저기 글의 레이아웃이 깨집니다. 앞으로 쓸데없이 멋부리지 않아야 겠습니다.
글을 조금 쓰다가 보니깐 역시나 눈에 거슬리는 것이 있습니다.
지금까지는 FreeBSD에서 작동하는 아파치에서 돌렸는데, 이제 굳이 FreeBSD로 돌여야 하나 싶습니다. 제가 마지막으로 사용한 이후에… 7.x 였을겁니다. 지금 10.x 버전인데.. 미묘하게 뭔가 많이 바뀌고, 특히나 패키지 설정이 바뀌었는데… 그다지 공부하고 싶은 흥미가 사라졌습니다.
요즘같은 세상에서.. Linux면되지… 그리서 좀 생각해보고 Digital Ocean 같은데로 가던가.. 아니면 국내 싼 VPS로 갈까 생각중입니다. (aws는 사양합니다..~)
진짜 오랜만에 인터넷 둘러보다가 가상화에서 CPU/ Memory 선택에 관한 글이 있어서 번역해봅니다. http://searchservervirtualization.techtarget.com/tip/Selecting-CPU-processors-and-memory-for-virtualized-environments 그런데 번역해놓고 보니깐… 이론강좌 비슷한 느낌이군요..
가상화 환경에서 CPU와 메모리를 선택하는 몇 가지 관점이 있다. 프로세스, 프로세스 속도, 코어의 수와 DIMM의 타입을 선택하면서 critical consideration을 동원할 것이다. 반드시 살펴봐야하는 전문적인 개요다.
가상화 환경에서 하드웨어를 선택하는 이 시리즈의 첫 번째 부분은, 이미 논의한 blade와 랙마운트 서버 중에 선택하기이다.
이제는 하드웨어 선택하는 과정을 봐야할 때고, CPU, 프로세서, 메모리를 구입할 때 고려하는 사항을 포함한다.
CPU를 구입할 때, 첫번째 선택은 어떤 브랜드(AMD or Intel?)을 선택할 것인가 이다. 지난 몇 년 동안, 많은 성능 연구들이 이 둘을 비교했다. 지속적인 프로세서 아키택처 변화를 통해서 AMD는 가끔은 Intel보다 앞서 나갔고 반대의 경우도 있다. Intel과 AMD 각각 Intel Virtualization Technology(Intel VT)와 AMD Virtualization이라는 virtualization extension 기능을 추가했고, 이것은 가상 서버의 실행을 보다 빨리하려는 시도였다.
Intel과 AMD 프로세서의 가장 큰 차이점은 물리 아키텍쳐이다. Intel은 front-side 버스 모델을 프로세서와 메모리 컨트럴러를 연결하는데 사용했고, 반면에 AMD는 메모리 컨트럴러를 hyper-transport를 통해서 각 프로세서에 통합하였다. 그리고 precessor family에 따라서 이 프로세서는 서로 다른 전력 소모율을 갖는다.
성능의 측면에서, 비슷한 속도와 기능과 코어를 가진 벤더를 비교한다면, Intel과 AMD는 아마도 같을 것이다. 어떤 성능 연구에서는 Intel 프로세서가 성능에서 우위를 가진다고 보이고, 다른 연구에서는 반대의 결과를 보 인다. Intel과 AMD 둘 다 VMWare ESX 호스트에서 아주 잘 동작한다, 그래서 하나를 고르는데는 브랜드 선호도가 중요한 요소이다. Intel과 AMD는 계속 새로운 프로세서 패밀리를 릴리스하고 있기 때문에, 둘중에 하나를 선택할 때에는 어떤 것이 가장 최신의 기술을 가지고 있는 것인지 체크할 필요가 있다.
그래서 어떤 CPU를 선택하야 하나요? 일반적으론 현재 운영중인 서버에서 많이 쓰는 브랜드를 선택하는 것도 좋은 생각이다. 이에 대한 이유는 프로세스가 다르다면 실행중인 가상머신을 하나의 호스트에서 다른 호스트로 이동할 수 없다(그럼에도 AMD demos live migration between Intel and AMD processors를 참고한다)에 나와 있다. 예를 들어, VM이 Intel 프로세서에서 생성된 머신이 AMD 프로세서에서 동작중인 호스트로 이동하면 일반적으로 crash가 발생한다. 만일 다른 브랜드를 섞어서 사용하기로 결정한다면, 호환성을 때문에 같은 브랜드의 프로세스를 클러스터로 분리하는 것이 최상이다.
프로세서를 구매할 때, AMD-V 또는 Intel-VT와 같은 가상화에 최적화된 모델을 선택하게 된다. 왜 가상화 확장 기능이 중요한지를 확실히 하기 위해서, CPU에서 ring이 어떻게 동작하는지 이애할 필요가 있다.
X86 운영체제는 코드가 잡을 수행하는 보호 레벨(protection level)을 제공하는 protection ring을 사용한다. 이 링은 가장 권한이 많은(Ring 0)부터 가장 권한이 적은(Ring 3)로 계층적으로 구성되고, CPU에 의해서 강제되고, 프로세스에 적용된다. 가상회되지 않은 서버에서는, OS는 Ring 0에 위차하고 있고 서버의 하드웨어를 소유한다. 그리고 어플리케이션은 Ring 3에서 실행된다. 가상화된 시스템에서는, 하이퍼바이저 또는 가상 머신 모니터(Virtual Machine Monitor, VMM)이 Ring 0에서 수행된다. 따라서 VM Guest은 Ring 1에서 실행된다. 따라서 대부분의 OS는 Ring 0에서 실행되고, VMM은 권한이 있는 명령(previleged instruction)과 Ring 0을 에뮬레이션을 이용하여 Guest OS에 Ring 0를 제공하며, 이를 통해서 Guest OS가 Ring 0에서 수행되고 있다고 속인다.
불행히도, 이 동작은 성능 저하를 가져오고, 이 때문에 Intel과 AMD가 이 문제를 해결하기 위해서 Intel VT와 AMD-V 확장 기능을 개발했다. 두 확장 셋은 그들의 CPU에 통합되어 있고, 따라서 VMM은 Ring -1이라고 불리는 새로운 Ring에서 실행된다. 여기서는 게스트 OS가 원래의 Ring 0에서 실행된다. 이런 CPU의 확장 기능은 성능을 향상 시킨다. VMM은 VM 게스트 OS가 Ring 0에서 실행되고 있기 때문에 Ring 0에서 실행되고 있다고 속일 필요가 더 이상 없으며, VMM과 충돌이 일어나지도 안는다. 가상 머신 호스트에서 최대한의 성능을 얻어내기 위해서 이런 가상화에 최적화된 확장 기능을 사용하는 CPU를 선택한다.
또한 AMD와 Intel이 새로운 Nested Page Tables(NPT)를 지원하는, 미래의 프로세서 릴리스에 귀를 기울인다. AMD 버전은 Rapid Virtualization Index(RVI)고 Intel은 Extended Page Tables(EPT)이다. 이 새로운 CPU 기술은 데이터베이스와 같은 커다란 어플리캐이션의 가상화의 성능 오버해드를 줄여준다.
다른 중요한 선택사항은 물리 CPU(Socket)와 CPU의 core의 갯수이다. 멀티코어 CPU는 하나의 물리 CPU 안에서 독립적으로 동작하는 다수의 코어로 구성된다. 기본적으로는 하나의 물리 CPU는 다수의 CPU로 전환된다. 예를 들어 2개의 quad-core CPU는 8개의 프로세서가 사용가능하다. CPU 브랜드와 모델에 따라서 이 코어는 가끔 하나의 캐쉬를 공유하기도 하고, 각 코어에 분리된 Level 2 캐쉬를 가지기도 한다. 대부분의 가상화 소프트웨어 벤더들은 소켓에 가진 코어의 갯수가 아닌 소켓의 갯수에 따라서 라이센스를 판매한다. 따라서 멀티코어 프로세서는 가상화에 아주 적합하다. 새로운 서버라면 멀티코어 CPU는 거의 표준이다.
또한 dual 또는 quad 코어 CPU를 선택해야할 필요도 있다. 아마도 보다 많은 코어가 좋다는 가정하에 dual-core 보다는 quad-core CPU를 선택할 것이다. 하지만 dual과 quad 코어 CPU에는 결정적인 차이가 있다. CPU 코어는 CPU 클럭 속도의 증가에 비례해서 증가하지 않는다. 3.2 GHz CPU는 1.6 GHz CPU보다 2배 빠르다. 하지만 quad-core는 단일 코어 CPU보다 4배 빠르지 않다. dual-core CPU는 단일 코어 CPU보다 대략 50% 빠르고(아마도 당신이 예상하는 100%가 아닌), quad-core CPU는 dual-core CPU보다 약 25% 빠르다. 더해서 dual-core CPU는 일반적으로 quad-core CPU보다 높은 클럭 스피드를 가진다. quad-core CPU는 과도한 별열을 가지며 결과적으로 단일 CPU와 dual-core CPU보다 높은 클럭을 가지지 않는다.
일반적으로 quad-core CPU는 가상 머신 호스트로 다음 두 가지 이유로 권장된다. 첫 번째는 대부분의 가상화 소프트웨어는 서버당 코어 개수가 아닌 소켓 개수를 기반으로 라이센스가 된다. 이것은 구입한 라이센스보다 더 많은 CPU를 사용할 수 있다는 것을 의미한다. 두 번째 이유는 호스트 서버에 보다 많은 코어를 갖는 것은 하이퍼바이저 CPU 스케쥴러가 VM이 요청한 CPU 요청을 좀 더 유연하게 스케쥴링을 할 수 있게 한다.
하지만, 어떤 상황에서는 quad-core CPU보다 dual-core CPU가 선호된다(예를 들어 만약 한 호스트에 6~8개 이상의 가상머신을 호스팅하지 않는 경우). dual-core CPU의 빠른 클럭 속도는 실행하는 VM의 속도를 빠르게 한다. 더해서 VM을 단일 가상 프로세서(vCPU)에 할당한다면, dual-core 프로세서는 보다 좋은 선택사항이 된다. 왜냐하면 하이퍼바이저에게 단일 vCPU는 멀티 vCPU보다 스케쥴링 하는게 더 쉽기 때문이다.
일반적으로 처음으로 다 써비리게되는 하드웨어 리소스가 메모리이기 때문에, 메모리에 인색하고 싶지는 않을 것이다. 호스트에 충분한 메모리가 없다면, 다른 리소스(CPU, 디스크, 네트워크 등등)가 충분해도, 호스트에 담을 수 있는 VM의 갯수에 제한을 받는다. 메모리 오버커밋(overcommit)이 가능한 가상화 소프트웨어가 있지만, 물리머신의 메모리를 다 써버린 경우 가상머신의 성능 저하때문에 권장되지 않는다(swap을 사용해서 생기는 성능 저하를 의미하는 듯).
서버 메모리 종류는 서버 지원에 명시되어 있다. 따라서 서버 스펙을 체크하가나 온라인 구매 가이드를 이용해 어떤 것이 이용 가능한지 확인한다. 서버에 얼마나 많은 메모리 슬롯이 있는지, 메모리가 쌍으로 설치될 필요가 있는지 체크한다.
서버에 다른 사이즈의 dual in-line memory modules(DIMMs)을 사용할 수 있으므로(512M, 1G, 2G 등등), 서버에 필요한 메모리의 크기에 맞춰서 DIMM 사이즈를 선택해야 한다. 보다 큰 메모리 DIMM(4G, 8G)은 작은 사이즈를 사용하는 것 보다 더 비싸다. 하지만 보다 작은 메모리 슬롯을 사용해, 향후 확장을 위한 공간을 남겨 놓을 수 있다. 한 번 DIMM 사이즈를 정하면, 여기에 고정된다. 최상의 결과를 원한다면 메모리 슬롯의 최대 사이즈 DIMM을 사용한다.
사이즈에 더 추가 한다면, 메모리 모듈의 최고 전송률(peak transfer rate)에 따른, 많은 다른 메모리 타입(PC2100, PC5300 등등)이 있다. 원래 “PC” 뒤의 숫자는 메모리 모듈이 데이터 전송에 지원하는 클럭 비율(rate)을 표시(예, PC133)하는데 사용되었다. 이건 나중에 최고 데이터 전송 비율(rate)을 Mbps로 바뀌었고, 따라서 PC5300으로 분류되는 메모리는 최고 데이터 전송 비율이 53000 Mbps를 의미한다. 대부분의 서버는 여러 다른 메모리 타입을 지원하고, 따라서 여유가 있다면, 사용 가능한 가장 빠른 메모리를 선택하는 것이 바람직하다.
(이 부분은 영 번영이 매끄럽지 못해서 원문도 같이 올려놓습니다.)
The final memory-related decision that you’ll have to make is between single, dual or quad-rank DIMMs. A memory rank is defined as a block of 64 bits, or 72 bits for error-correcting code (ECC) memory, created by using the DRAM chips on a DIMM. For example, single-rank DIMMs combine all chips into a single block, while dual-rank DIMMs split the chips into two blocks. Dual-rank DIMMs improve memory density by placing the components of two single-rank DIMMs in the space of one module, typically making them cheaper than single-rank DIMMs.
마지막 메모리 관련 결정사항은 single, dual 또는 quad-rank DIMM 중에서 하나를 선택하는 것이다. 메모리 랭크(rank)는 에러 검출 코드(error-correctiong code: ECC) 메모리(DIMM의 DRAM 칩에서 만들어지고 사용되는)에 사용되는 64 비트 또는 72 비트의 블럭으로 정의된다. 예를 들어 단일 랭크 DIMM은 모든 칩이 단일 블럭으로 구성되고, 반면에 dual-rank DIMM은 칩이 두개의 블럭으로 분리된다. daul-rank DIMM은 두 single-rank을 한 모듈의 같은 공간에 위치시켜 메모리 집적도를 항샹시킨다. 이는 일반적으로 single-rank DIMM보다 보다 가격이 싸게 된다.
불행이도, 어떤 서버 칩센은 특정 개수의 랭크만 지원한다. 예를 들어 만일 서버에 있는 메모리 버스가 4개의 DIMM 슬롯을 가진다면, 칩셋은 단지 두개의 dual-rank DIMM 또는 내개의 single-rank DIMM만 지원할 수 있다. 만일 두개의 dual-rank DIMM이 설치된다면 마지막 두 슬롯은 확장할 수 없다. 만일 DIMM 슬롯에 설치된 랭크의 총 개수가 칩셋에서 지원하는 최대 갯수를 넘긴다면, 서버는 안정적으로 동작하지 않을 것이다.
그래서 어떤 DIMM 타입을 선택할까요? 단일 랭크 DIMM은 서버의 최대 메모리 용량을 사용할 수 있고, 최대의 성능을 낼 수 있다. 하지만 고집적도이기 때문에 보다 비싸다. dual-rank DIMM은 보다 싸다. 하지만 전체적인 시스템 용량을 제한하고, 향후 업그레이드 옵션을 제한한다. 보다 비싼 single-rank DIMM을 최적화를 위해서 사용할 필요가 있다. 만일 안된다면 dual-rank의 DIMM도 비슷하게 잘 동작할 것이다. 어떤 서버에서는 같은 뱅크(bank)에 있지 않아도 single과 dual-rank DIMM을 섞어서 사용할 수 있다(물론 이러한 방법은 권장하지 않아도…). 그리고 최상의 결과를 위해서 모든 슬롯에 같은 랭크 타입을 선택한다.
마지막으로, 시장에서는 몇가지 메모리 제조사들이 있다. 그리고 한 서버 안에서 브랜드를 섞지 않을 것이 좋다. 기존 운영중인 서버에 있는 같은 종류의 OEM 메모리를 구입하거나, 다른 벤더로 모두 교체한다. 메모리 설정과 선택은 매우 복잡하다. 따라서 항상 서버 하드웨어 벤더와 서버에 맞는 올바른 설정을 만들기 위해서 상의한다.
이 시리즈의 다음 파트는 가상머신 호스트의 스토리지 옵션인, 네트워크와 스토리지 I/O 어텝터에 대해서 다룹니다.
Ironic이 아직 인큐베이팅이라서 그런지 아직 안되는게 많네요.
근데 아마 가장 첫번째로 닥치는 문제는 개발환경 만들기군요 ㅎㅎ
정신 건강을 위해서 아직 시도하지 않는게 좋을 듯 합니다.
만일 내가 회사를 세운다면.. 세울 원칙..
ps. 만일 회사를 세운다면.. 아마 10년 뒤에..??