아틀란타 서밋에서 CloudScaling의 발표를 보다가 OpenContrail에 관심이 생겨 조사해봤는데, 그들의 블로그에 클라우드 네트워킹을 이해하는데 아주 좋은 자료가 있어 번역해 봤습니다. 아주 어색하니 주의하시길..
클라우드 네트워크를 가상화하는 데 사용되는 기술은 빠르게 진화하고 있다. 서로 다른 기술의 다른 점을 알아내고, 그들의 접근 방법의 장점과 장점을 이해하는 것은 대게 사소한 일이 아니다.
여기서는 1) 레거시의 가상화된 환경에서 사용되는 네트워크 가상화 기술에 대해서 설명하고 2) 레거시와 클라우드 데이터 센터 간의 차이에 대해서 이야기하고 3) 클라우드 데이터 센터에서 사용되는 가상화 기술을 비교한다.
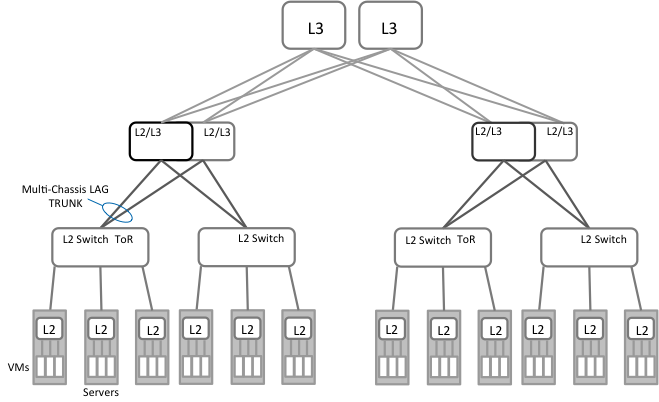
Figure 1: Legacy Datacenter Network
그림 1은 서버 가상화를 실행하는 기존의 데이터 센터를 보여준다.
일반적으로 네트워크는 여러 L2 도메인으로 분할된다. 각각의 L2 도메인은 ToRs (Top of Rack) 집합으로 구성되고, 이것은 한 쌍의 Aggregation switch로 연결된다. 가상화된 서버는 ToR 스위치에 연결되어 있다. “End-of-Row” 스위치를 포함한 여러 변형도 있다. 하지만 근본적으로는 작고 잘 정의된 구간의 L2 도메인으로 분할이 된다. 이 디자인은 tree topology를 만든다. 따라서 각각의 노드는 기본적으로 심각한 over-subscribtion 상태에 놓이게 된다. 네트워크의 성능은 “capacity planning” 프로세스를 통하여 각 aggregation switch에 link, ports 등을 추가하여 관리된다. 대부분의 경우, 네트워크는 그들이 같은 아키텍처를 기반으로하는 경우에도, 데이터 센터의 다른 부분에서는 다르게 보인다.
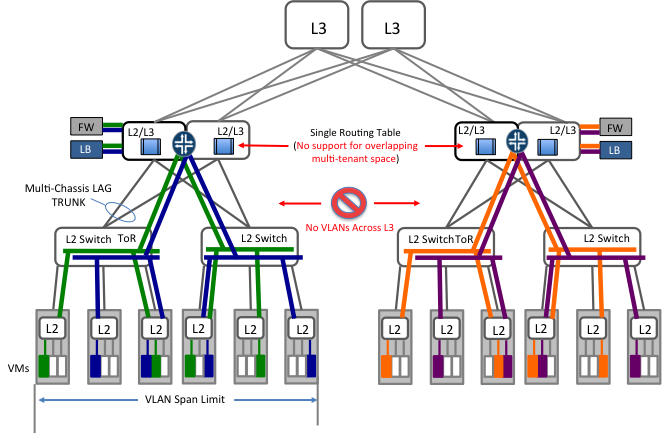
Figure 2: Network Virtualization in legacy Datacenters
그림 2는 네트워크 가상화가 어떻게 이러한 레거시 네트워크에서 구현되는지 보여준다. 일반적으로 Ethernet trunk(모두 또는 선택된 VLAN을 전송한다)는 ToR 스위치에서 각 가상 서버까지 연결된다. 서버 내에서 생성된 가상 머신은 하나 또는 그 이상의 VLAN에 연결된다. 그림에서 보는 것과 같이 VLAN의 구간(span)은 L2 도메인의 크기에 제한된다.
대부분의 경우 L2/ L3 aggregation switch에서는 하나의 라우팅 영역이 지원된다. 모든 VLAN 간 트래픽은 aggregation switch에서 라우팅된다. 패킷 필터 (ACLs, access control list)도 일반적으로 각 VLAN 인터페이스 포트에 있는 aggregation switch에서 적용이 된다.
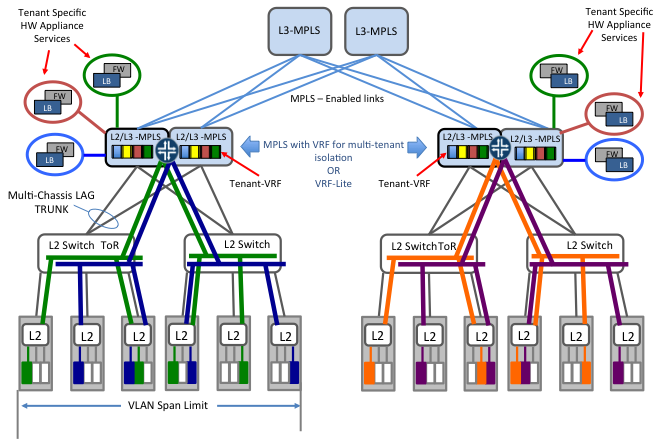
Figure 3: Multi-tenancy in legacy datacenter
멀티 테넌트간에 주소 공간의 중복(overlappng-ip)을 지원하는 시나리오를 사용하기 원하는 사람들은 VRF-lite(Virtual Routing Forwarding without MPLS) 또는 정식으로 MPLS와 같이 VRF를 사용하여 aggregation 계층에 각 테넌트를 위한 독립된 라우팅 공간을 만든다.
많은 경우 이 방법은 테넌트에 dedicated된 물리 방화벽과 로드밸런서 어플라이언스를 포함한다. 그림 3에서 보는 것처럼, 코어 계층은 테넌트를 여러 L2 도메인에 걸처 확장하기 위해 MPLS(LDP등 control plane 프로토콜과 같이) 활성화가 필요할 것이다.
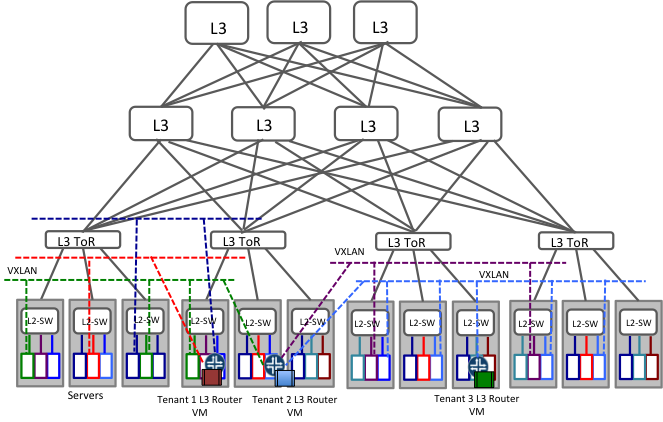
Figure 4: Basic Network Virtualization in Cloud Datacenters
많은 요즘 클라우드 데이터센터는 ToR 스위치에 L3(Routing)을 사용하여 만들어졌다. 이것은 원래 OSPF나 BGP 같은 L3 라우팅 프로토콜이 밀접하게 서로 맞물린 토폴로지(예, CLOS)를 쉽게 지원하고, 여러 비용이 동등한 경로로 flow를 분산하여 대칭적으로(균등하게) IP fabric의 효율적인 사용을 돕기 때문에 가능하다. 또한 IP 네트워크는 여러 데이터센터 및 기타 등등에 걸칠 수 있는 유비쿼터스(Ubiquity)의 특성 때문에 선택된다. 이러한 데이터센터에서는 L2 도메인이 부족하기 때문에 VLAN을 만드는 것은 아주 적합하지 않다. 따라서 VXLAN(또는 NVREG)와 같은 이더넷 프레임을 IP 네트워크를 통해 전송되는 IP 패킷으로 encapsulation하는 encapsulation 방법이 일부 채택되고 있다.
그림 4에서 각각 같은 색의 점선은 같은 L2 네트워크를 표시한다. 각 가상화된 서버에서 실행되는 soft switch(virtual swift)만이 일반적인 L2다. L2 LAN을 떠나가는 모든 트래픽은 가상 머신에서 실행되는 소프트웨어 라우터로 보내진다. 어떤 경우에는 가상 스위치에 LAN 간에 트래픽을 스위칭하는 기능이 있을 수 있다. 하지만 게이트웨이는 일반적으로 가상머신으로 실행되는 소프트웨어 라우터이다.
이러한 설정에서, 각각의 테넌트는 잠재적으로 게이트웨이로 동작하는 소프트웨어 라우터를 가진다. 그들은 필요한 용량에 따라서 추가 라우터를 얻는다. 라우터는 패킷 필터링, NAT(Network Address Translation)과 같은 정책을 구현한다.
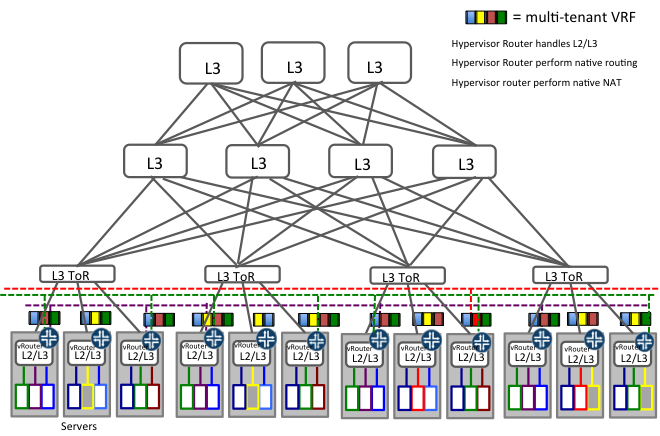
Figure 5: Multi-tenant Cloud Datacenters with advanced server based capabilities
그러나, 많은 소프트웨어 라우터를 운영의 복잡성을 방지 하는데 도움을 주는 기술이 있다.
그림 5는 가상화된 서버 내부의 각 소프트웨어 스위치들이 어떻게 switching, routing, inline packet en(de)capsulation을 실행하는지 보여준다. 따라서 각 가상화된 서버안에 있는 커널 모듈이 직접적으로 NAT, 패킷 필터링, 외부 접속을 수행하는 multiple-VRF 라우터처럼 동작합니다. 이러한 deployment에서는 많은 소프트웨어 라우터를 생성하면서 자연스럽게 따라오는 운영 이슈에 직면하지 않습니다.
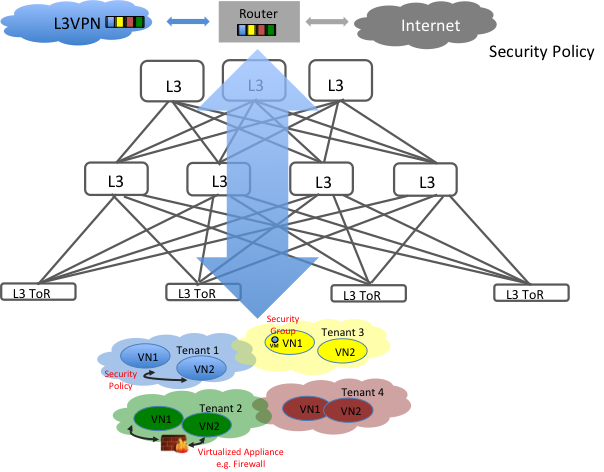
Figure 6: Virtual Services within multi-tenant cloud datacenters
그림 5에 설명된 기술을 활용한 deployment는 클라우드 데이터센터 안의 가상머신을 멀티 테넌트로 쉽게 추상화 할 수 있다. 각각의 테넌트는 네트워크간에 보안정책 안에서 여러 개의 가상 네트워크를 가질 수 있다. 이 테넌트는 또한 각 인스턴스 기반의 security group을 가지거나 가상 네트워크간에 필요하면 가상화된 서비스 인스턴스(예, virtual firewall, virtual DDos 방어기 등등)를 추가할 수 있다.
일반적으로 이러한 데이터센터는 외부 퍼블릭 네트워크에 게이트웨이로 동작할 IP en(de)capsulation 및 MBGP(multi-protocol BGP)를 지원하는 표준 라우터가 필요하다. 따라서 이 접근법에서는 라우터 안의 ASIC의 극한의 전송 능력이 활용된다.
이 접근법의 또 다른 장점은 게이트웨이 라우터의 동일한 세트를 통해 서비스 제공자 L3VPN 인프라와 쉽게 통합된다는 것이다.
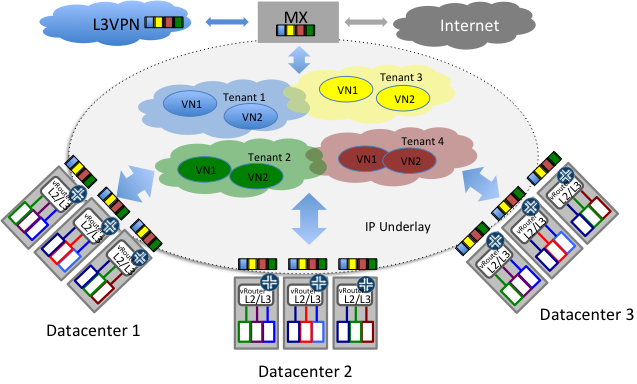
Figure 7: Multi-tenant multi-datacenter cloud network
그림 7은 네트워크 가상화 기술이 어떻게 여러 데이터센터 너머로 쉽게 멀티 테넌트 클라우드 인프라를 구성하는지 보여준다. 일반적으로 다른 데이터센터를 서로 연결하는 하부의 구성요소(underlying fabric)은 IP다. IP encapsulation을 사용하는 클라우드 가상화 기술은 쉽게 여러 데이터센터간에 확장할 수 있다.
모든 데이터 센터는 일반적인 라우터 게이트웨이를 사용하여, 외부 네트워크 또는 서비스 제공 업체 L3VPN 인프라에 액세스 할 수 있다.
결론
중요한 클라우드 서비스 제공 업체와 대형 엔터프라이즈 네트워크는 구식의 L2-L3 분리에 기반에서 네트워크 scaling에 인위적인 제약조건을 두지 않는 클라우드 네트워크 가상화 기술에 관심을 기울이고 있다. 그들은 멀티 데이터센터, scale-out 방식으로 대용량으로 운영되는 멀티 테넌트 L2-L3 지원하는 기술과 솔류션을 찾고있다. 그래서 이 기술은, 오픈소스화 되는 것 뿐만 아니라 프로토콜 통신(interaction)에서도 공개 표준에 기반을 두어 명확하게 설명되는 것이 필요하다.
흥미롭게도, OpenContrail과 같이 사용되는 이 기술(그림 5, 6, 7)은 이러한 요구사항중 많은 것에 만족된다. 시간은 Vendor/ Provider/ Enterprise가 자신의 전반적인 선택을 이끌어줄 어떤 전략적 기술을 선택할지 알려줄 것입니다.
원문: http://opencontrail.org/comparing-network-virtualization-techniques-available-in-the-cloud/
이 글을 읽고 막연하게만 생각했던 SDN이 어떤 것이고 어디서 필요한 것인지 감을 잡았고.. 앞으로 우리가 어떻게 네트워크 모델을 잡아야 하는지 길이 보이는군요.. ^^ 자 보이시나요?


