스터디 하는 김에 발번역 해봤습니다.
Chater 15. XMLHttpRequest
XMLHttpRequest(XHR)은 브라우저 레벨 API로, 클라이언트가 JavaScript를 이용하여 데이터를 전송을 scripting할 수 있게 한다. XHR는 IE5에 처음으로 등장해, AJAX(Asynchronous JavaScript And XML)의 기반 기술이 되었으며, 최근 웹 어플리케이션의 핵심 요소가 되었다.
XMLHTTP는 모든 것을 바꾸었다. DHTML에서 “D”를 의미한다. 이를 사용하여 서버의 데이터를 비동기로 받을 수 있으며, 클라이언트에 document state를 보존할 수 있다. Outlook Web Access(OWA)팀은 브라우저에서 win32와 같은 rich application을 만들고 싶어 했고, IE에 이 기술이 들어가 AJAX가 되므로써 현실화 되었다. – OWA - A catalyst for web evolution Jim Van Eaton
XHR 이전에는, 클라이언트와 서버간의 데이터의 전송 또는 상태 업데이트를 하려면, 웹페이지를 refresh 해야만 되었다. XHR를 통해서는, 이 작업이 비동기와 어플리케이션의 JavaScript 코드로 완전히 제어된다. XHR을 사용하면 페이지를 빌드하는 것을 뛰어넘어, 브라우저에서 interactive web application을 만드는 것을 가능하게한다.
하지만, XHR의 힘은 브라우저 안에서 비동기 통신을 가능하게하는 것 뿐만 아니라, 이를 단순하게 만드는 힘도 있다. XHR은 브라우저에 의해 지원되는 어플리케이션 API이다. 브라우저는 connection management, protocol negotiation, formatting of HTTP request과 아래의 일을 자동으로 처리한다.
- 브라우저는 connection establishment, pooling and termination를 관리한다.
- 브라우저는 최적의 HTTP(S) 전송 프로토콜 (HTTP 1.0, 1.1, 2.0)을 선택한다.
- 브라우저는 HTTP caching, redirect and content-negotiation을 처리한다.
- 브라우저는 보안, 인증, 개인정보 보호등을 처리한다.
- 그리고 기타 등등…
기존의 programming과 비교하면, XHR로 통신하는 브라우저 측면의 기술들을 모두 직접 또는 라이브러리를 통하여 구현해야했다. 하지만 XHR를 통하면, 자연스럽게 브라우저에서 기본으로 제공하는 위의 기능을 사용하게 된다.
모든 로우 레벨의 자세한 사항에 대한 걱정이 없이, 어플리케이션의 비지니스 로직(요청 초기화, 요청의 진행 관리, 서버로 부터 리턴된 데이터 처리)에 집중할 수 있다. 단순한 API와 모든 브라우저를 통해 언제 어디서나 자료를 주고 받을 수 있는 기능은 XHR를 브라우저 네트워킹의 “swiss army knife”로 만들었다.
결과적으로, 최근 모든 네트워킹 유스 케이스(스크립트로 다운로드, 업로드, 스트리밍, 실시간 알림)이 XHR위해서 가능하고, 구현되어 왔다. 물론 XHR이 모든 케이스에 가장 효율적인 전송 방법은 아니다. 그렇긴 하더라도 새로운 브라우저의 네트워킹 API를 사용할 수 없는 경우, 오래된 클라이언트의 fallback 전송 방법으로 자주 쓰인다. 이런 마음가짐으로 XHDR의 최근 기능들의 유스 케이스와 성능, 해야할 것과 하지말아야할 것을 살펴보자.
전체 XHR API와 기능에 대한 분석은 이 문서의 범위를 벗어난다. 우리의 관심사는 성능이다. XMLHttpRequest API에 대한 공식 W3C 표준을 참고하라. http://www.w3.org/TR/XMLHttpRequest/
Brief History of XHR
이름과는 다르게 XHR은 XML이 특별하게 연결되어 있지 않다. XML Prefix는 XHR이 IE5에 들어가는 MSXML 라이브러리로 알려진 한 부분으로 처음 출시하게된 흔적이다.
릴리스하기 몇일 전에 아주 중요한 기능이 요구되기 전까지는… 아주 좋은 시절이었습니다. MSXML 라이브러리는 IE에 들어간 것을 알았고, XML팀에 도와줄만한 몇몇의 괜찮은 연락처를 가지고 있었습니다. 그때 그 팀을 이끌고 있는 Jean Paoli에게 연락했고, 우리는 그 것을 MSXML 라이브러리의 일부로 싣기위해 꽤 빨리 빠져들고 있었습니다. 이것이 XMLHTTP라는 이름이 어디서 왔는지에 대한 진실입니다. 그 것들은 대부문 HTTP에 관한 것이었고 특별히 XML에 연관되어 있지도 않았습니다. 이름에 XML을 넣어야 하는 것은 출시를 위한 가장 쉬운 변명이었죠. – The story of XMLHTTP Alex Hopmap
Mozilla도 Microsoft에 대응하여 그들의 XHR 모델을 구현하여 XMLHttpRequest interface로 발표했다. Safari, Opera 등 다른 브라우저도 따랐고, XHR은 모든 주요 브라우저에 de facto 표준이 되었다. 이름이 변경되지 않은 이유는 이 때문이다. 사실 XHR의 공식 W3C Working Draft 표준은 2006에 겨우 발표되었고, XHR이 나온 이후에야 널리 쓰이게 되었다.
인기와 AJAX 혁명에 핵심 역할을 담당함에도 불구하고, 초기 버전의 XHR은 제한된 기능(텍스트만 허용하는 데이터 전송, 업로드 기능에 대한 제한된 지원, cross-domain에 대한 기능 부제)을 제공했다. 이러한 단점들을 보충하기 위해 “XMLHttpRequest Level 2” 초안이 아래의 새로운 기능을 추가하여 2008년에 발표되었다.
- 요청 타입아웃 지원
- binary와 text 데이터 전송 지원
- Application이 재정의 가능한 media type과 response encoding 지원
- 각각 요청에 대한 진행 모니터링 이벤트 지원
- 효율적인 파일 업로드 지원
- 안전한 cross-origin request 지원
2001년에, “XMLHttpRequest Level 2” specification은 원래 XMLHttpRequest working draft에 통합되었다. 따라서 XHR 레퍼런스를 찾는데 버전 1 또는 2를 찾는다면, 이 둘은 차이 없다. 이제는 동일한 하나의 규약이다. 사실 모든 XHR2의 새로운 기능은 같은 이름인 XMLHttpRequest API로 더 많은 기능을 제공한다.
새로운 XHR2 기능은 현재 모든 최근 브라우저에 의해서 지원된다. - see http://caniuse.com/xhr2 따라서 XHR를 쓴다면 언제든지, 묵시적으로 XHR2 표준을 사용한다.
Cross-origin resource sharing(CORS) XHR는 자동으로 캐싱, 리다이렉트 처리, content negotiation, 인증 등 무수히 많은 저수준의 기능을 핸들링하는 브라우저 레벨 API이다. 첫 번째로 application API를 비지니스 로직에 집중하는 것을 쉽게 하며, 두 번째로 어플리케이션 코드에 브라우저를 sandbox로 활용하고 보안과 정책 제한 사항을 강제할 수 있다.
XHR 인터페이스는 각 요청에 대해 HTTP 구문 제한사항을 강제한다. 어플리케이션은 데이터와 URL을 제공하고, 브라우저는 요청을 포멧하고 각 연결의 전체 life cycle을 관리한다. 유사하게, XHR API가 어플리케이션에 custom HTTP 헤더를 추가(setRequestHeader()를 통해서)하는 것에 반해서, 어플리케이션에 제공되지 않은 많은 보호된 헤더가 있다.
- Accept-Charset, Accept-Encoding, Access-Control-*
- Host, Upgrade, Connection, Refer, Origin
- Cookie, Sec-, Proxy- 그리고 더 많음…
브라우저는 안전하지 않은 헤더를 재정의 하는 것을 거부할 것이다. 이것은 어플리케이션이 가짜 user-agent, user 또는 요청이 만들어진 곳(origin)으로 위장하지 못하도록 보장한다. 사실은 원래의 헤더를 보장하는 것은 특별하게 중요하며, 이것은 “same-origin policy”의 핵심 요소로 XHR Request에 적용되어 있다.
모든 “origin”은 어플리케이션 프로토콜, 도메인 이름, 포트 번호 세가지로 정의된다. 예를 들어 (http, example.com, 80), (https, example.com, 443)은 서로 다른 origin으로 간주된다. 보다 더 자세한 것은 The Web Origin Concept를 참고한다.
Same origin policy는 시작은 간단하다. 브라우저는 인증 토큰, 쿠기, 기타 private metadata와 같은 다른 어플리케이션에 유출되어서는 안되는 사용자의 데이터를 저장한다. 예를들면 동일한 sandbox가 아니면 example.com에 있는 임의 스크립트가 thirdparty.com의 사용자 데이터를 접근하고 수정할 수 있다.
이 명확한 문제점을 설명하면, 초기 버전의 XHR은 동일한 origin의 요청만 제한하였다. 즉 request의 origin은 요구된 리소스의 origin과 동일해야 한다. example.com에서 시작된 XHR은 동일한 example.com에 있는 리소스 만 요청할 수 있다. 다른 방법으로 만일 동일 origin 선행 조건이 실패하면, 브라우저는 단순하게 XHR 요청 시작을 거부하며 에러를 발생시킨다.
하지만, 만일 필요하다면, same origin policy는 또한 XHR의 유용성을 위해서 제약 사항을 제공하는 공간을 설정할 수 있다. 서버가 다른 origin에 있는 스크립트에 대한 리소슬ㄹ 제공하고 싶다면 어떨까? 여기서 “Cross-Orign Resource Sharing”(CORS)이 나온다. CORS는 클라이언트 측의 cross-origin request에 대한 안전한 opt-in(사전 동의) 메커니즘을 제공한다.
// script origin: (http, example.com, 80)
var xhr = new XMLHttpRequest();
xhr.open('GET', '/resource.js'); // ---- [1]
xhr.onload = function() { ... };
xhr.send();
var cors_xhr = new XMLHttpRequest();
cors_xhr.open('GET', 'http://thirdparty.com/resource.js'); // ---- [2]
cors_xhr.onload = function() { ... };
cors_xhr.send();
- 1 Same-origin XHR request
- 2 Cross-origin XHR request
CORS request는 스크립트를 실행하는 곳과 요청되는 곳의 URL만 다르고 동일한 XHR API를 사용한다. 위의 예제에서는 스크립트는 (http, example.com, 80)에서 실행되었고, 두 번째 XHR 요청은 (http, thirdparty.com, 80)에 있는 resource.js를 접근하고 있다.
CORS 요청에 대한 opt-in(사전 동의) 인증은 보다 낮은 레이어에서 제어된다. 요청이 만들어지면, 브라우저는 자동으로 보호된 Origin HTTP 헤더를 추가한다. 이것은 요청이 어디서(어떤 origin에서) 만들어 졌는지를 알린다(advertise). 다음 순서로 원격 서버에서는 origin header를 검사하고 요청을 허락할지를 결정하고 Access-Control-Allow-Origin로 리턴한다.
=> Request
GET /resource.js
HTTP/1.1
Host: thirdparty.com
Origin: http://example.com // ---- [1]
...
<= Response HTTP/1.1 200 OK
Access-Control-Allow-Origin: http://example.com // ---- [2]
...
- 1 브라우저가 자동으로 설정한 origin 헤더
- 2 서버가 설정한 사전동의 헤더
위의 예제에서는, thirdparty.com은 적절한 response에 포함된 access control header를 통하여 사전 동의하에 example.com과 리소스를 공유하기로 결정했다. 다른 방법으로 접근을 허용하지 않기를 원한다면, 간단하게 Access-Control-Allow-Origin 헤더를 뺀다. 그러면 클라이언트 브라우저는 자동으로 요청 보내기가 실패할 것이다.
만일 다른 서버가 CORS를 인지하지 못한다면, 클라이언트는 항상 opt-in 헤더가 있는지 검사하기 때문에, 클라이언트 요청은 실패한다. 특별한 케이스로 CORS는 어떤 origin에서도 접근을 허용하기 위해서 wildcard(Access-Control-Allow-Origin: *)로 리턴하는 것을 허용한다. 하지만 이 정책을 활성하기전에 두번 생각하라.
이것으로 모든게 끝났다. 맞나요? 완전하지는 않지만 정리는 되었다. CORS는 서버가 CORS를 알고 있는 것을 확실히 하기 위해, 많은 추가 보안 대비사항을 가지고 있다.
- CORS 요청은 cookie와 HTTP 인증과 같은 user credentials를 포함하지 않는다.
- 클라이언트는 “simple cross-origin request”를 요청하는 것이 제한되어 있다. 이것은 허용된 메소드(GET, POST, HEAD)와 XHR에 의해서 보내고 읽어지는 HTTP 헤더를 접근을 제한한다.
쿠키와 HTTP 인증을 활성화 하기 위해서는, 클라이언트는 반드시 요청을 만들때 XHDR 객체의 추가 속성(withCredentials)를 설정 해야한다. 그리고 서버는 반드시 어플리케이션에 private user data 포함을 허용하는 적절한 헤더(Access-Control-Allow-Credentials)로 응답해야한다. 유사하게, 클라이언트가 custom HTTP 헤더를 읽거나 쓰기 위해서 또는 “non-simple method”를 request에 사용한다면 반드시 third party 서버로 부터 사전 요청(preflight request)을 통해서 권한을 요청해야 한다.
=> Preflight request
OPTIONS /resource.js HTTP/1.1 // ---- [1]
Host: thirdparty.com
Origin: http://example.com
Access-Control-Request-Method: POST
Access-Control-Request-Headers: My-Custom-Header
...
<= Preflight response
HTTP/1.1 200 OK // ---- [2]
Access-Control-Allow-Origin: http://example.com
Access-Control-Allow-Methods: GET, POST, PUT
Access-Control-Allow-Headers: My-Custom-Header
...
(actual HTTP request) // ---- [3]
- 1 권한을 확인하기 위한 preflight OPTIONS
- 2 third party origin에서 preflight 성공 응답
- [3] 실제 CORS request
공식 W3C CORS 규약은 언제, 어디서 preflight request가 반드시 사용 되어야 하는지 정의하고 있다. “simple” request는 생략할 수 있다. 그러나 이것을 유발할 다양한 조건 있고, 권한을 확인하기 위해 네트워크의 latency를 유발하는 초소한의 full roundtrip이 추가된다. 좋은 소식은 한번 preflight 요청이 맺어지면, 클라이언트가 감지할 수 있고, 각각의 요청에 대해서 같은 확인을 피할 수 있다.
CORS은 모든 최근 브라우저가 지원한다. see http://caniuse.com/cors 다양한 CORS 정책과 구현에 대한 자세한 내용은 공식 W3C 표준을 참고한다. http://www.w3.org/TR/cors/
Downloading data with XHR
XHR은 텍스트와 바이너리 데이터를 전송할 수 있다. 실제로 브라우저는 다양한 데이터 타입에 대한 자동 인코딩과 디코딩을 제공한다. 따라서 어플리케이션은 브라우저가 자동으로 디코딩할 수 있는 타입에 대하여 XHR에 절적히 인코딩된 데이터를 직접 제공할 수 있게 한다.
- ArrayBuffer - 고정 길이 바이너리 데이터 버퍼
- Blog - 변경 불가능한 binary large object
- Document - 파싱된 HTML 또는 XML 문서
- JSON - 간단한 데이터를 표현하는 JavaScript 객체 표현
- Text - 텍스트 스트링
브라우저는 HTTP content-type negotiation을 통하여 적절한 데이터 타입(예를 들면 application/json을 JSON 객체로 디코딩)을 유추하거나 어플리케이션이 명시적으로 XHR 요청을 시작할 때 데이터 타입을 정의한다.
var xhr = new XMLHttpRequest();
xhr.open('GET', '/images/photo.webp');
xhr.responseType = 'blob'; // ---- [1]
xhr.onload = function() {
if (this.status == 200) {
var img = document.createElement('img');
img.src = window.URL.createObjectURL(this.response); // ---- [2]
img.onload = function() {
window.URL.revokeObjectURL(this.src); // ---- [3]
}
document.body.appendChild(img);
}
};
xhr.send();
- 1 리턴 타입을 blob으로 설정
- 2 blob에서 Object를 생성하고 이미지 소스로 설정
- [3] 이미지가 로드되면 오브젝트 해제
이미지를 base64 encoding에 의존하지 않고 native format으로 전송하고, 이미지 element를 데이터 URI에 의지하지 않고 페이지에 추가했다. 여기에 네트워크 전송 오버헤드나 JavaScript로 전송 받은 데이터를 조작하는 인코딩 오버해드는 없다. XHR API를 사용하여 JavaScript에 비하여 효율이고, 동적 어플리케이션, 데이터 종류에 상관없이 스크립팅이 가능하다.
Blob 인터페이스는 HTML File API의 한 부분이고 어떠한 종류의 데이터(binary or text) chunk에 대한 opaque reference로 동작한다(interface hiding이란 의미일 듯). 이에 의하여 blob reference는 다음의 제한된 기능을 가진다. 크기, MIME Type를 알 수 있고 보다 작은 blob로 분할할 수 있다. 하지만 실제로 다양한 JavaScript API 사이에 효율적인 데이터 교환 메커니즘을 제공한다.
Uploading data with XHR
XHR를 이용해서 데이터를 업로드하는 것은 간단하고 모든 데이터 타입에 대해 효율적이다. 실제로 코드는 XHR request의 send()를 호출할 때 데이터 객체를 전달하는 것을 제외하고 동일하다.
var xhr = new XMLHttpRequest();
xhr.open('POST','/upload');
xhr.onload = function() { ... };
xhr.send("text string"); // ---- [1]
var formData = new FormData(); // ---- [2]
formData.append('id', 123456);
formData.append('topic', 'performance');
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
xhr.send(formData); // ---- [3]
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
var uInt8Array = new Uint8Array([1, 2, 3]); // ---- [4]
xhr.send(uInt8Array.buffer); // ---- [5]
- 1 간단한 텍스트 업로드
- 2 FormData API를 이용하여 동적으로 폼을 생성
- [3] 서버로 multipart/form-data 객체를 전송
- [4] unsigned 8 byte integer array(ArrayBuffer) 타입을 생성
- [5] 바이트 덩어리를 서버로 전송
XHR의 send() 함수는 DOMString, Document, FormData, Blob, File, ArrayBuffer 중 하나를 파라미터로 받는다. 자동으로 적동한 인코딩을 수행하고, 적절한 HTTP content-type을 설정하고, request를 보낸다. 바이너리 데이터를 보내거나 파일 업로드 기능을 사용자에게 제공할 필요가 있나요? 간단합니다. 객체에 대한 참조를 얻고, XHR로 전달하면 된다. 사실 약간의 추가 작업을 통해, 큰 파일을 작은 덩어리로 분리하여 보낼 수 있다.
var blob = ...; // ---- [1]
const BYTES_PER_CHUNK = 1024 * 1024; // ---- [2]
const SIZE = blob.size;
var start = 0;
var end = BYTES_PER_CHUNK;
while(start < SIZE) { // ---- [3]
var xhr = new XMLHttpRequest();
xhr.open('POST', '/upload');
xhr.onload = function() { ... };
xhr.setRequestHeader('Content-Range', start+'-'+end+'/'+SIZE); // ---- [4]
xhr.send(blob.slice(start, end)); // ---- [5]
start = end; end = start + BYTES_PER_CHUNK;
}
- [1] 어떤 blob 데이터(바이너리 또는 텍스트)
- [2] chunk 크기를 1MB로 설정
- [3] 1MB씩 증가하면서 데이터를 전
- [4] 업로드할 데이터 사이즈를 알림
- [5] XHR를 통해서 데이터를 1MB씩 전송
XHR는 request streaming을 제공하지 않는다. 이 말은 send()를 호출할때 전체 payload를 제공해야한 다는 것이다. 하지만, 위의 예제에서는 간단한 우회 방법을 설명했다. 파일을 분할하고 여러 XHR 요청을 이용하여 데이터를 업로드 한다. 이런 구현 패턴은 true request streaming에 대한 대체 방법으로는 의미가 없다. 하지만 그럼에도 불구하고 일부 어플리케이션에서는 사용 가능한 솔루션(viable solution)이다.
큰 파일을 작은 파일로 나눠서 업로드하는 것은 연결 상태가 안정적이지 못하거나 간간히 끊기는(intermittent) 조건에서는 보다 튼튼한 API를 제공하는 좋은 방법이다. 예를 들어, 만일 chunk가 연결이 끊겨서 실패하면, 어플리케이션은 시작부터 전체 전송을 재시작하는 대신에, 해당 chunk의 업로드를 재시도하거나 재시작 할 수 있다.
Monitoring download and upload progress
네트워크 연결 상태는 가끔 끊기거나, 지연이 생기고, 대역폭이 변화가 심할 수 있다. 그러면 XHR 요청이 성공했는지, timeout인지 또는 실패인지 어떻게 알 수 있을까? XHR request는 현재 생태를 알려주는, 진행 상황 이벤트를 listening하는 API를 제공한다.
Table 15-1. XHR progress events Event type Description Times fired loadstart Transfer has begun once progress Transfer is in progress zero or more error Transfer has failed zero or once abort Transfer is terminated zero or once load Transfer is successful zero or once loadend Transfer has finished once
각각의 XHR 전송 요청은 loadstart로 시작하고, loadend 이벤트로 끝난다. 그리고 그 사이에 한 번 이상의 추가 이벤트가 발생하여 전송 상태를 알려준다. 따라서 진행 상황을 모니터링 하려면 어플리케이션에서 XHR 객체의 JavaScript 이벤트 리스너를 등록한다.
var xhr = new XMLHttpRequest();
xhr.open('GET','/resource');
xhr.timeout = 5000; // ---- [1]
xhr.addEventListener('load', function() { ... }); // ---- [2]
xhr.addEventListener('error', function() { ... }); // ---- [3]
var onProgressHandler = function(event) {
if(event.lengthComputable) {
var progress = (event.loaded / event.total) * 100; // ---- [4]
...
}
}
xhr.upload.addEventListener('progress', onProgressHandler); // ---- [5]
xhr.addEventListener('progress', onProgressHandler); // ---- [6]
xhr.send();
- [1] request 타임아웃을 5000ms로 설정(기본값: 타임아웃 없음)
- [2] 성공적인 요청에 대한 callback 등록
- [3] 실패한 요청에 대한 callback 등록
- [4] 전송 진행율 계산
- [5] 업로드 진행상황 이벤트 callback 등록
- [6] 다운로드 진행상황 이벤트 callback 등록
load 또는 error 이벤트는 XHR 전송의 최종 상태를 알리기 위해 한 번 발생한다. 반면에 progress 이벤트는 자주 발생하며, 전송 상황을 추적하기 위한 API가 제공된다. loaded 속성을 total과 계산하여 전송된 데이터 양를 계산할 수 있다.
전송된 데이터를 계산하기 위하여, 서버는 response에 content-length를 반드시 제공해야 한다. 정의에 의하면 응답의 전체 크기는 알 수 없기 때문에, 단위 조각의 전송 진행 상황은 추측할 수 없다.
또한, XHR request는 기본 timeout을 가지고 있지 않다. 이 말은 request는 영원히 진행중 상태에 있을 수 있다는 말이다. best practice로 어플리케이션에서는 항상 의미있는 timeout을 설정하고, 에러를 처리하라!
Streaming data with XHR
어떤 경우에는 어플리케이션이 데이터가 순차적으로 증가하는 스트림 데이터가 필요하거나 처리할 필요가 있다. 서버가 사용 가능하면 클라이언트에서 데이터를 업로드하거나 서버에서 데이터가 다운로드 되면 처리하는 경우에 필요하다. 안타깝게도 이건 중요한 유스케이스임에도 불구하고, 지금 현재로선 간단하고, 효과적이고 여러 브라우저에서 가능한 XDR streaming을 위한 API가 없다.
- send 메소드는 업로드의 경우 전체 payload가 올 것을 예상한다.
- response, responseText, responseXML 속성은 streaming을 위해 디자인되지 않았다.
Streaming은 공식 XHR 규약 안에서 전혀 공식적인 유스케이스가 아니었었다. 결과적으로 클라이언트에서 서버로 streaming을 위한 API는 없고, 수동으로 작은 단위로 분리해서 업로드하는 것이 되었다. 유사하게 XHDR2 규약에서는 서버에서 부분(partial) response를 읽을 수 있는 기능을 제공하지만, 구현은 효율적이지 않고, 아주 제한되어 있다. 아주 안좋은 뉴스이다.
좋은 소식은 수평선에서 희망이 떠오르고 있다는 것이다! 스트리밍 지원의 부족에 대한 지원은 XHR이 잘 알고 있는 있는 제한사항 중 최상위 유스 케이스이고, 이 문제를 설명하는 작업이 진행중이다.
웹 어플리케이션은 시간에 따라 들어오는 sequence of data를 포함하여 다양한 형태의 데이터를 얻고 조작해야한다. 이 규약은 기본적인 Stream과 Stream에서 발생하는 에러와 stream을 만들고 읽는 프로그래밍 방법을 표현한다. – W3C Streams API
XHR과 Streams API의 조합은 브라우저에서 XHR Streaming을 효과적으로 가능하게 한다. 하지만, Streams API는 아직 논의중이며, 아직 어떠한 브라우저에서도 사용 가능하지 않다. 따라서 여기에 우리는 갇혔을까? 음.. 완전히는 아니다. 이전에도 언급 했듯이, XHR를 이용한 streaming 업로드는 선택사항이 아니다. 하지만 XHR를 사용하여 제한된 스트리밍 다운로드 지원은 가능하다.
var xhr = new XMLHttpRequest();
xhr.open('GET', '/stream');
xhr.seenBytes = 0;
xhr.onreadystatechange = function() { // ---- [1]
if(xhr.readyState > 2) {
var newData = xhr.responseText.substr(xhr.seenBytes); // ---- [2]
// process newData
xhr.seenBytes = xhr.responseText.length; // ---- [3]
}
};
- 1 상태와 진행 알림에 등록
- 2 부분 응답에서 새로운 데이터를 추출
- [3] 처리된 데이터 크기 업데이트
위의 예제는 대부분의 최근 브라우저에서 동작할 것이다. 하지만 성능은 훌륭하지 않고, 구현에 대한 많은 caveats and gotchas(권고 사항와 알아낸 것)가 있다.
- 수동으로 받은 바이트 양을 추적하는 것과 데이터를 잘랐던 것을 명심하라. responseText은 전체 응답을 버퍼링힌다! 작은 양의 데이터 전송에서는 이슈가 되지 않을 것이다, 하지만 큰 다운로드와 특히 모마일 디바이스 같은 메모리 제약사항이 있는 곳은 문제가 된다. 버퍼된 응답을 해제하는 유일한 방법은 요청을 끝내고 새로운 것을 여는 것 뿐이다.
- 부분 응답은 responseText 속성을 통해서만 읽을 수 있다. 이 제한사항은 텍스트 전송에만 적용된다. 바이너리 전송에 대한 부분 응답을 읽을 수 있는 방법은 없다.
- 한 번 부분 데이터를 읽으면, 반드시 메시지 경계선을 확인해야 한다. 어플리케이션 로직은 반드시 고유의 데이터 포멧을 정의하고 버퍼링하고 스트림을 분석해서 각각의 메시지를 추출해야한다.
- 받은 데이터를 어떻게 버퍼링 하는가는 브라우저마다 서로 다르다. 어떤 브라우저는 데이터를 바로 해제하고 어떤 브라우저는 작은 응답을 버버링하고 보다 큰 덩어리로 해제한다.
- 순차적으로 읽기를 허용하는 content-type이 브라우저마다 다르다. 어떤 브라우저는 “text/html”에 대해 허용하고, 어떤 브라우저는 “application/x-javascript”에서만 작동한다.
간단하게, 현재의 XHR 스트리밍은 효과적이지도 않고, 편리하지도 않고, 작업을 나쁘게 만든다. 공통의 스팩이 없는 것은 또한 구현이 브라우저마다 다른다는 것을 의미한다. 결과적으로 최소한 Streams API가 사용 가능하기 전까지, XDR은 스트리밍에 맞지 않다.
실망할 필요는 없다! XHR은 이 영역에는 맞지 않지만, 스트리밍 유스 케이스에 최적화된 다른 전송 방법을 가지고 있다. Server-Sent Events는 서버에서 클라이언트로 보낸 스트리밍 텍스트 데이터에 대한 API를 제공한다. 그리고 WebSocket은 효과적이고, 양방향 스트리밍을 바이너리, 텍스트 데이터에 대해서 지원한다.
Proprietary API’s and extensions for XHR streaming
Firefox, Internet Explorer 둘 다 그들만의 “streaming XHR extension”을 제공한다.
- Firefox는 moz-chunked-text와 moz-chunked-arraybuffer를 제공한다.
- Internet Explorer는 ms-stream을 지원한다.
XHR 오프젝트의 responseText의 위의 속성을 지정하여, 두 브라우저는 전체 응답을 버퍼링하는 것을 방지할 수 있고, 바이너리 응답에 대해서 XDR 오프젝트에서 순차적으로 읽기를 지원한다. 불행하게도 Chrome, Opera 또는 다른 인기있는 브라우저에는 동일한 기능을 제공하는 API가 없다. 결과적으로 XHR 스트리밍은 크로스 브라우저 어플리케이션에 대해서는 아직 현실에 적용하기 적당하지 않다.
Real-time notification and delivery
XHR은 서버와 클라이언트의 업데이트를 동기화 하는 단순하고 효과적인 방법을 제공한다. 필요한 경우에 언제든지 클라이언트는 업데이트 하기 위한 적절한 데이터를 포함한 XHR 요청을 서버로 보낸다. 하지만 반대의 상황의 문제는 보다 어렵다. 서버에서 데이터가 업데이트되면, 서버는 어떻게 클라이언트에게 알릴까?
HTTP에서는 서버가 클라이언트에 새로운 연결을 시작하는 방법을 제공하지 않는다. 결과적으로 실시간 알림을 받기 위해서는 클라이언트는 서버 데이터 업데이트를 위해서 poll을 하던가, 서버가 새로운 알림이 생겼을 때 사용할 수 있게 streaming 전송을 이용해야 한다. 불행하게도 이전 섹션에서 이미 보았듯이, XHR Streaming 지원은 제한적이므로 XHR polling을 사용한다.
“real-time”은 서로 다른 어플리케이션에는 서로 다른 의미로 정의된다. 어떤 어플리케이션은 sub-milisecond overhead를 요구하고, 다른 것에서는 분단위 지연도 허용된다. 최상의 전송 방법을 결정하기 위해서, 첫번째로 어플리케이션에 대한 지연(latency)과 overhead 목표를 정하라!
Polling with XHR
서버에서 업데이트 되는 것을 가져오는 가장 간단한 방법 중에 하나는 클라이언트에서 주기적으로 검사하는 것이다. 클라이언트는 주기적으로 업데이트를 검사하는 백그라운드 XHR 요청을 만들 수 있다. 새로운 데이터가 서버에 있다면, response에 리턴되고 없다면 아무것도 없다.
polling은 간단하게 구연할 수 있지만, 주기적인 호출은 또한 매우 비효율적이다. polling 간격을 선택하는 것은 매우 critical하다. 긴 polling 간격은 업데이트를 가져오는 것이 지연되는 반면에 잛은 간격은 필요없는 트래픽과 클라이언트와 서버에 높은 부담을 준다. 가장 간단한 polling 예제를 보자.
function checkUpdates(url)
{
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() { ... }; // ---- [1]
xhr.send();
}
setInterval(checkUpdates('/updates'), 60000); // ---- [2]
최적의 polling 간격은 무엇일까? 그건 없다. 폴링 주기는 어플리케이션의 요구사항과 효율성과 메시지 지연사이의 tradeoff를 포함하고 있다. 결과적으로 polling은 polling 간격이 긴 어플리케이션에 적합하다. 새로운 이벤트는 주기적인 예측가능한 비율로 도작하고 전송되는 payload는 크다. – 추가 HTTP overhead와 메시지 전송 지연은 서로 상쇄된다.
Modeling performance and XHR polling
지연과 XHR polling 오버헤드간의 tradeoff를 설명하기위해, XHR polling을 서버 메시지 업데이트를 위해 사용하는 간단한 이메일 어플리케이션을 생각해보자. 구현은 다음과 같다.
- 매 60초마다 클라이언트는 업데이트 확인을 위해 XHR를 보낸다.
- 각 XHR은 클라이언트가 알고있는 가장 최근 메시지 ID 포함한다.
- 서버는 클라이언트의 아이디를 메시지 리스트와 비교한다.
- 서버는 새로운 메시지 리스트 또는 빈 리스트(업데이트가 없을 경우)를 응답한다.
평균 메시지 latency 지연은 얼마인가?
클라이언트가 체크하기 전에 서버에 새로운 메시지가 도착하면, 지연은 클라이언트와 서버간의 latency로 최소화된다. 반대로 새로운 메시지는 클라이언트가 체크한 후 도착할 수 있다. 이 경우 메시지는 다음 클라이언트의 체크(60초)까지 대기한다. 따라서 메시지 도착이 랜덤이라면, 평균 메시지는 클라이언트에서 가져가기 전까지 서버에서 30초를 기다린다.
polling overhead는 얼마인가?
평균적인 HTTP 1.x 요청은 추가로 800 바이트의 요청과 응답 오버헤드가 있다(“Measuring and controlling protocol overhead” 참고). 클라이언트가 로그인 되어 있기 때문에, 추가 인증 쿠기와 메시지 ID를 가지고 있다(50 바이트라고 치자).따라서 새로운 메시자가 없는 요청은 약 850 바이트를 리턴할 것이다. 이제 10,000 클라이언트를 가지고 있고, 모두 60초 간격으로 폴링한다고 생각하자.
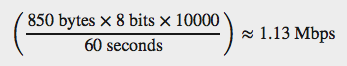
각 클라이언트는 각 요청마다 850 바이트 데이터를 전송하고, 이것은 초당 167 요청으로 변환된다. 서버에 ingress througput은 1.13 Mbps로 유지된다. 그리고 이것은 어떤 클라이언트에도 어떤 새로운 메시자가 없어도 발생하는 고정 값이다.
30초의 지연이 너무 높은가? polling 간격을 낮출 수 있지만, 이렇게 하면 보다 높은 throughput과 오버헤드를 발생한다. 같은 10,000 클라이언트에서 1초의 간격은 60Mbps 이상의 트래픽을 발생시킨다! 간단하게 말하면 폴링 간격이 길지 않다면, 폴링은 비싸다.
Long-polling with XHR
주기적인 폴링 시도에는 필요없고 빈 체크가 많을 가능성을 포함하고 있다. 이런 생각으로 폴링 작업 흐름에 약간의 수정을 가했다. 업데이트가 없을 때 빈 리스트를 리턴하는 대신, 연결을 업데이트가 있을 때까지 idle 상태로 유지하는건 어떨까?
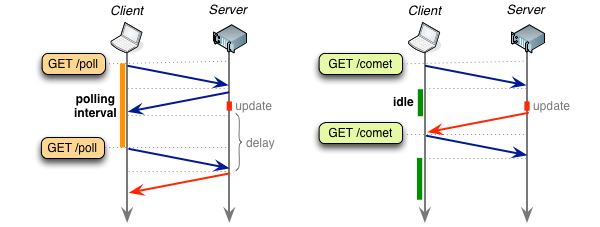
오래 유지되는 HTTP request(“a hanging GET”)을 이용하여 서버에서 브라우저에 데이터를 푸쉬하는 것에 사용되는 기술은 일반적으로 “Comet”으로 알려져 있다. 하지만 아마 reverse AJAX, AJAX push, HTTP push라는 다른 이름으로도 만날 수 있다.
업데이트가 있을 때까지 연결을 열린 채로 유지(long-polling)로 인해서, 서버에서 데이터가 발생하면 즉시 클라이언트로 바로 보내질 수 있다. 결과적으로 long-polling은 메시지 지연과 빈 리스트 체크를 없앨 수 있는 가장 좋은 시나리오이다. 업데이트가 전달되면, long-polling 요청은 종료되고 클라이언트는 다른 long-poll 요청을 시작한다. 그리고 다음 메시지가 있을 때 까지 기다린다.
function checkUpdates(url) {
var xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.onload = function() { // ---- [1]
...
checkUpdates('/updates'); // ---- [2]
};
xhr.send();
}
checkUpdates('/updates'); // ---- [3]
- [1] 전송받은 업데이트를 처리하고, 새로운 long-pool XHR를 시작한다.
- [2] 다음 업데이트에 대한 long-poll 요청을 시작한다. 그리고 영원히..
- [3] 최초 long-pool XHR 요청을 시작한다.
이걸로 long-polling은 주기적인 polling에 비하여 항상 최고의 선택일까? 메시지 도착율을 알고 있고, 일정한 경우가 아니라면 long-polling은 메시지 전달 지연이 항상 더 좋다. 만일 이게 가장 중요한 부분이라면 long-polling이 승자다.
다른 측면으로, 약간은 뉴앙스적인 측면에서 오버헤드에 대한 논의가 더 필요하다. 첫 번째로 각각 전달되는 메시지는 각각의 독립적인 HTTP request 이므로, 역시 같은 HTTP 오버헤드를 유발한다. 하지만, 메시지 전달 비율이 높다면, long-polling은 주기적인 polling보다 더 많은 XHR 요청을 발생한다!
long-polling은 메시지 지연을 최소화 하여, 다이내믹하게 메시지 도착 비율을 적용할 수 있다. 이 것이 아마도 원하는 동작 방식일 것이다. 만일 메시지 지연에 대한 오차를 허용한다면, 폴링은 아마도 보다 효율적으로 전달될 것이다. 예를들어 메시지 업데이트 비율이 높다면, polling은 간단히 “message aggregation” 메커니즘을 제공하고, 이것은 요청 수를 감소시키고 모마일 디바이스의 베터리 소모를 적게한다.
예제에서, 모든 메시지가 동일한 우선순위나 지연 요구사항을 가지는 것은 아니다. 결과적으로 서버의 low-latency 업데이트는 통합하고, 높은 우선순위의 업데이트는 즉시 시작하는 복합적인 적략을 사용하기를 원할 것이다. “Nagle and effcient server push” 참고
Facebook Chat via XHR long-polling
실제로, long-polling은 XHR를 통해 실시간으로 알리는 방법으로 가장 널리 쓰이는 방법 중에 하나가 되었다. 가장 효율적인 방법이 아닐지 몰라도, 이것은 간단하고, 튼튼하고, XHR이 가능한 어떤 브라우저에도 사용이 가능하다. 2008년에 발표된 Facebook Chat와 같은 인기있는 제품에서도 이 방법을 통해서 발표되었다.
사용자에서 다른 사용자에로 보내는 텍스트를 얻기위해 취한 방법은, 각 facebook 페이지의 iframe을 로드하고, 그 iframe이 포함된 JavaScript는 HTTP Get을 persistent connection을 통해서 요청한다. 그 connection은 서버가 클라이언트로 보낼 데이터가 있기 전까지는 리턴하지 않는다. 요청이 방해받거나 timeout이 발생하면 다시 연결한다. 이것은 새로운 기술을 의미하는 건 아니다. 이것은 Comet, XHR long-polling, BOSH의 한 변형이다. – Facebook Chat Facebook Engineering Blog
오늘날, 같은 기능을 Server-Sent Event와 WebSocket을 통하여 보다 효율적인 방법으로 할 수 있다. XHR은 아직도 많은 실시간 프레임워크의 일반적인 실패 대비 전략이다. 만일 모든 다른 방법이 실패하면, long-polling이 해결책이다.
XHR use cases and performance
XMLHttpRequest는, 페이지를 빌드하는 것부터, 브라우저에서 interactive 웹 어플리케이션을 만드는 것 까지 가능하게 한다. 첫번째로 브라우저안에서 비동기 통신을 가능하게 한다. 이것이 이제 중요하기도 하고, 프로세스를 단순하게 한다. 스크립트된 HTTP 요청을 보내고 제어하는 것은 몇 줄의 JavaScript 코드면 가능하고 브라우저는 나머지 모든 것을 처리한다.
- 브라우저는 HTTP 요청을 format하고 response를 분석한다.
- 브라우저는 관련된 보안 정책(same-origin)을 강제한다.
- 브라우저는 content-negotiation(gzip 같은)을 처리한다.
- 브라우저는 request와 response 캐쉬를 처리한다.
- 브라우저는 인증, 리다이렉트 및 기타 등등을 처리한다.
XHR은 다재다능하고 HTTP request-response 사이클을 따르는 전송에 대한 고성능 데이터 전송 방법이다. 인증이 필요하고, 압축 전송이 필요하고, 나중을 위해서 캐쉬가 필요한 데이터를 가져올 필요가 있는가? 브라우저는 이 모든 것을 포함한 다른 것들도 처리하여, 우리는 어플리케이션 로직에 집중할 수 있게 한다.
하지만, XHR은 제한사항을 가지고 있다. 이미 보았듯이, 스트리밍은 아직 한번도 XHR 표준에 공식 유스케이스가 된 적이 없고 지원도 제한적이다. XHR을 이용한 스트리밍은 효율적이지도 않고 편리하지도 않다. 다른 브라우저는 서로 다르게 동작하라 것이다. 그리고 특히나 바이너리 streaming은 불가능하다. 요약하면 XHR은 스트리밍에 좋지 않다.
비슷하게, XHR를 이용하여 실시간 업데이트를 전달하는 단 하나의 최고의 전략은 없다. 주기적은 폴링은 높은 오버해드와 메시지 latency 지연을 가져오고, long-polling은 지연 시간이 작지만, 각 메시지는 서로 독립된 HTTP request 이므로, 각 메시지마다 동일한 오버헤드를 가지고 있다. 낮은 지연시간과 낮은 오버해드를 위해 XHR Streaming은 필요하다!
결과적으로 XHR은 실시간 전달을 위한 인기있는 메커니즘이지만, 최상의 성능을 보이는 전달 방식은 아니다. 최근 브라우저는 간단하고 보다 효율적인 Server-Sent Events와 WebSocket와 같은 방법들을 지원한다. 따라서 XHR polling이 필요한 특별한 이유가 없는 경우는, 그 것을 사용하라.